Tapis ETL
Tapis ETL is a convenience layer on top of Tapis Workflows that enables users to create automated ETL pipelines with a single request. Tapis ETL leverages Tapis Workflow resources (pipeline and tasks) to manage the entire ETL process; from ingesting data files from the configured source system, to tracking their status as they are processed by user-defined batch computing jobs and transferring the results to the configured destination system.
Overview
Introduction
An ETL pipeline (Extract, Trasform, Load) is a workflow pattern commonly used in scientific computing wherein data is extracted from one or more sources, transformed by some set of processes, and output data produced by those processes are archived to some final destination.
Tapis ETL is a framework built on top of Tapis Workflows that enables users to create fully automated and parallel ETL Pipelines in the Tapis ecosystem. Once a pipeline is configured, simply drop off data and manifest files on the source system. Tapis ETL will run the HPC jobs according to the manifests and archive the results to the configured destination system. For an example of how to get started, jump to the quickstart section.
Glossary
Here we introduce the Tapis ETL standard terminology for ETL pipelines
Note
Local denotes any resource (systems, files, etc) situated at TACC. Remote denotes any resource (systems, files, etc) NOT situated at TACC.
Manifests - Files that track the progress of one or more data files through the various phases of an ETL Pipeline. They are responsible for managing and mantaining the state between pipeline runs.
Remote Outbox - The source system that contains the data files you want to process. This system is commonly a Globus endpoint or S3 bucket.
Local Inbox - The system where data is processed
ETL Jobs - Batch computing jobs that will be run sequentially on HPC/HTC systems against the data files in a manifest.
Local Outbox - The system where the output will be staged for transfer to the destination system
Remote Inbox - The destination system where output data will be archived
ETL System Configuration - A collection of systems responsible for storage of data and manifest files. It is the general term for remote and local inboxes and outboxes.
Data System - Component system of an ETL System Configuration responsible for the storage of data.
Manifests System - Component system of an ETL System Configuration responsible for the storage of manifests.
Phase - A distinct stage of a single Tapis ETL Pipeline run:
ingress,transform,egressResubmission - Rerunning a specific phase or phases of an ETL pipeline for a given manifest.
Pipeline Run - A single run of an ETL pipeline
How it works

- Step 0 must be completed by a user or other external workflow asynchronous Tapis ETL.
Data files to be processed are placed in the data directory of the configured Remote Outbox. A manifest is generated for those files (by a user or a script) and placed in the Remote Outbox’s manifest directory
- Steps 1-4 are managed by Tapis ETL:
Tapis ETL then checks the Remote Outbox manifests directory for new manifests and transfers them to the manifests directory of the Local Inbox. The files enumerated in the new manifests on the Local Inbox are then transferred over to the data directory of the Local Inbox
A single unprocessed manifest is chosen by the ETL Pipeline (according to the manifest priority) and the files therein are then staged as inputs to the first batch computing jobs. Each batch computing job definied in the ETL Pipeline definition will then be submitted to the Tapis Jobs API; the first of which processes the data files in the manifest.
After all jobs run to completion, a manifest is generated for each of the output files found in the data directory of the Local Outbox.
All data files enumerated in that manifest are then transferred to the data directory of the Remote Inbox.
Phases
- Tapis ETL Pipelines run in 3 seperate phases. The Ingress, Transform, and Egress Phases.
Ingress Phase - Tapis ETL inspects the Remote Outbox for new data files and transfers them over to the Local Inbox.
Transform Phase - A single data file or batch of data files is processed by a series of user-defined ETL Jobs
Egress Phase - The output data files from the ETL Jobs are tracked and transferred from the Local Outbox to the Remote Inbox
User Guide
This section shall serve as the primary technical reference and comprehensive step-by-step guide for the seting up, creating, and managing ETL Pipelines with Tapis ETL.
0. Prerequisites
If you have already satisfied the prerequisites, you can skip to the ETL Systems Configuration section.
0.1 Data Center Storage and Compute Allocations
Your project may need a storage allocation on some storage resource (for example at TACC: Corral, Stockyard, or one of our Cloud-based storage resources) to serve as the project’s Local Inbox and Outbox. The size of the required allocation greatly depends on the size of the files that will be processed in the pipeline.
Your project may also need one or more allocations on a compute system (for example at TACC: such as Frontera, Stampede2, Lonestar5, or one of cloud computing systems. ETL Jobs run by Tapis ETL will use the allocations specified in the ETL Job definitions.
0.2 Users and Allocations
When Tapis ETL runs an ETL Job, it does so as the owner of the ETL Pipeline. This Tapis user must be mapped to a valid user with a valid allocation on the underlying compute system or the Transform Phase of the ETL Pipeline will always fail.
0.3 TapisV3 Client Setup
Throughout the User Guide, we will be creating TapisV3 objects. For all TapisV3 requests, both cURL and tapipy instructions will be available.
Tapipy usage and installation instructions can be found at https://pypi.org/project/tapipy/.
curl -H "Content-type: application/json" -d '{"username": "your_tacc_username", "password": "your_tacc_password", "grant_type": "password" }' https://tacc.tapis.io/v3/oauth2/tokens
export JWT=your_access_token_string
from tapipy.tapis import Tapis
# Create python Tapis client for user
t = Tapis(base_url= "https://tacc.tapis.io",
username="your_tacc_username",
password="your_tacc_password")
# Call to Tokens API to get access token
t.get_tokens()
0.4 Tapis Workflows Group
Tapis ETL uses Tapis Workflows’ Groups to manage access (creating, deleting, running) ETL Pipelines. If you do not own or belong to a group, create it following the instructions below.
Creating a Group (createGroup)
Create a file in your current working directory called group.json with the following json schema:
{
"id": "<group_id>",
"users": [
{
"username":"<user_id>",
"is_admin": false
}
]
}
Note
You do not need to add your own Tapis id to the users list. The owner of the Group is added by default.
Replace <group_id> with your desired group id and <user_id> in the user objects with the ids of any other Tapis users that you want to have access to your workflows resources.
Warning
Users with is_admin flag set to true can perform every action on all Workflow resources in a Group except for
deleting the Group itself (only the Group owner has those permissions)
Submit the definition.
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups -d @group.json
import json
from tapipy.tapis import Tapis
t = Tapis(base_url='https://tacc.tapis.io', username='<userid>', password='************')
t.get_tokens()
with open('group.json', 'r') as file:
group = json.load(file)
t.workflows.createGroup(**group)
Note
- Section 0 Punch List
Valid allocation for your project on the compute and storage resources
Valid user with a valid allocation on the compute resources
Set up a Tapis client (Bash or Python)
Create or belong to a valid Tapis Workflows Group
1. ETL Systems Configurations
In this section, we discuss ETL System Configurations. At the end of this section, we will explain how to create and configure all Remote and Local ETL System Configruations for an ETL Pipeline.
Note
ETL System Configurations are by far the most complex part of creating an ETL Pipeline. Do not be discouraged! The initial complexity is a small price to pay for the ease with which ETL Pipelines are operated with Tapis ETL.
An ETL System Configuration is a collection of systems that are responsible for the storage of data files (Data System) and the storage of manifest files (Manifest System).
- There are 4 ETL System Configurations for every ETL Pipeline:
The Remote Outbox - Where input data files to be processed are staged
The Local Inbox - Where input data files are processed
The Local Outbox - Where output data files are staged
The Remote Inbox - Where output data files are transferred
Every ETL System Configuration is composed of 2 systems: A Data System and a Manifests System. These systems generally have a one-to-one correspondence with a Tapis Systems.
Note
There are many different possible ETL System Confguration setups for an ETL Pipeline. It is entirely possible to have a single Tapis System representing all systems in an ETL Pipeline. How you set up your ETL System Configurations depends entirely upon where the data is and how you want to process it.
Common ETL System Configurations Setup
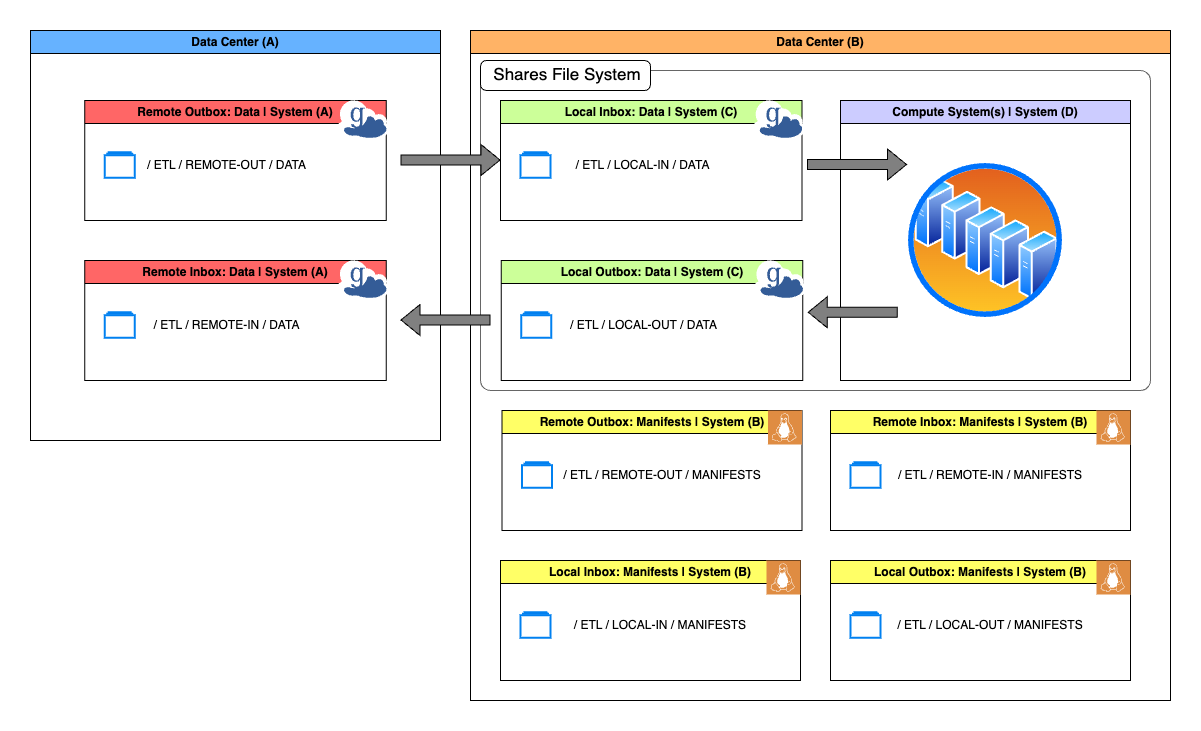
Above is an illustration of the most common ETL System Configuration setup. You will notice that there are four distinct Tapis Systems; System(A) System(C) are Globus endpoints, System(B) is a Linux system, and System(D) is the ETL Job execution system (also Linux) that shares a file system with Systems(C). It is worth noting that some of the Data and Manifests Systems for some ETL System Configurations (Remote Inbox, Remote Outbox, etc.) have corresponding Tapis System that are located at entirely different data centers.
1.1 Create Tapis Systems for the ETL System Configurations
Before we discuss ETL System Configurations in depth, we will first create all of the Tapis Systems that will be used by Tapis ETL to run our ETL Pipeline. We will be using a simplified single-data center model for this pipeline. In this setup, the Local Inbox, Local Outbox, and compute system will use LoneStar6 (LS6) as the host and the Remote Inbox and Remote Outbox will use the LS6 Globus Endpoint as the host.
Simplified ETL System Configurations Setup

Follow the instructions below to create the necessary Tapis Systems for your ETL Pipeline.
This globus Tapis System will be used as the Data System for both of the Remote ETL System Configurations (Remote Inbox, Remote Outbox) in our pipeline.
Creating a Globus System for an ETL Pipeline
Create a file named onsite-globus-system.json in your current working directory that contains the json schema below.
{
"id": "etl.userguide.systema.<user_id>",
"description": "Tapis ETL Globus System on LS6 for data transfer and storage",
"canExec": false,
"systemType": "GLOBUS",
"host": "24bc4499-6a3a-47a4-b6fd-a642532fd949",
"defaultAuthnMethod": "TOKEN",
"rootDir": "HOST_EVAL($SCRATCH)"
}
import json
from tapipy.tapis import Tapis
t = Tapis(base_url='https://tacc.tapis.io', username='<userid>', password='************')
t.tokens.get_tokens()
with open('onsite-globus-system.json', 'r') as file:
system = json.load(file)
t.systems.createSystem(**system)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/systems -d @onsite-globus-system.json
Register Globus Credentials for the System
Once you have successfully created the system, you must then register credentials for the system in order for Tapis to access it on your behalf. Follow the instructions found in the Registering Globus Credentials for a System section.
Once you have successfully registered credentials for the system, you should be able to list files on the system.
Once you have succesfully listed files for this system, move onto the instructions for System (B)
This linux Tapis System will be used as the Manifests System for all ETL System Configurations in our pipeline. It will also serve as the exec system on which we will run our pipelines ETL Jobs.
Creating a Linux System for an ETL Pipeline
Create a file named onsite-linux-system.json in your current working directory that contains the json schema below.
{
"id": "etl.userguide.systemb.<user_id>",
"description": "Tapis ETL Linux System on LS6 for manifests and compute",
"systemType": "LINUX",
"host": "ls6.tacc.utexas.edu",
"defaultAuthnMethod": "PKI_KEYS",
"rootDir": "HOST_EVAL($SCRATCH)",
"canExec": true,
"canRunBatch": true,
"jobRuntimes": [
{
"runtimeType": "SINGULARITY",
"version": null
}
],
"batchLogicalQueues": [
{
"name": "ls6-normal",
"hpcQueueName": "normal",
"maxJobs": 1,
"maxJobsPerUser": 1,
"minNodeCount": 1,
"maxNodeCount": 2,
"minCoresPerNode": 1,
"maxCoresPerNode": 2,
"minMemoryMB": 0,
"maxMemoryMB": 4096,
"minMinutes": 10,
"maxMinutes": 100
},
{
"name": "ls6-development",
"hpcQueueName": "development",
"maxJobs": 1,
"maxJobsPerUser": 1,
"minNodeCount": 1,
"maxNodeCount": 2,
"minCoresPerNode": 1,
"maxCoresPerNode": 2,
"minMemoryMB": 0,
"maxMemoryMB": 4096,
"minMinutes": 10,
"maxMinutes": 100
}
],
"batchDefaultLogicalQueue": "ls6-development",
"batchScheduler": "SLURM",
"batchSchedulerProfile": "tacc-apptainer"
}
Use one of the following methods to submit a request to the Systems API to create the Tapis System.
with open('onsite-linux-system.json', 'r') as file:
system = json.load(file)
t.systems.createSystem(**system)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/systems -d @onsite-linux-system.json
Register Credentials for the System
Once you have successfully created the system, you must then register credentials for the system in order for Tapis to access it on your behalf. Follow the instructions found in the Registering Credentials for a System section.
Once you have successfully registered credentials for the system, you should be able to list files on the system.
1.2 ETL System Confguration Components
Every ETL System Configuration is composed of two parts. The Data System and the Manifests System.
1.2.1 Data System
The Data System is a collection of properties that define where where data files are located (or where data files are supposed to be transferred) as well as how to perform integrity checks on that data. Below is an example of the Data System of a Remote Inbox ETL System Configuration (Manifests System ignored to simplify the schema)
{
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
"integrity_profile": {
"type": "done_file",
"done_files_path": "/ETL/REMOTE-OUTBOX/DATA",
"include_patterns": ["*.md5"],
"exclude_patterns": []
},
"include_patterns": ["*.txt"],
"exclude_patterns": []
}
"manifests": {}
}
}
system_id- The ID of Tapis System on which:data files are stored (Outbox systems)
data files are to be transferred (Inbox systems)
path- The path to the directory on the Tapis System where data files are stagedinclude_patterns- An array of glob patterns that are used to filter filenames. All files matching the glob patterns are considered by Tapis ETL to be data files.exclude_patterns- An array of glob patterns that are used to filter filenames. All files matching the glob patterns are considered by Tapis ETL to be non-data files.
1.2.1.1 Data Integrity Profile
Every Data System has a Data Integrity Profile. The Data Integrity Profile is a set of instructions that informs Tapis ETL on how it should check the validity of all data files in the data path. There are 3 ways in which Tapis ETL can perform data integrity checks:
byte_check- Checks the actual size (in bytes) of a data file against it’s recored size in a manifestchecksum- Takes the hash of a data file according to the specified hashing algorithm and checks that value against the value of the checksum in a manifest. This is an expensive process for large data files. The data integrity check type should only be used if data files are small or if absolutely necessary.done_files- Checks that a data file has a corresponding done file in which:the done file matches a set of glob patterns
the done file’s filename contains the corresponding data file’s filename as a substring
Below are some example schemas of Data Systems with different Data Integrity Profiles
{
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
"integrity_profile": {
"type": "byte_check"
},
"include_patterns": ["*.txt"],
"exclude_patterns": []
}
"manifests": {}
}
}
{
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
"integrity_profile": {
"type": "checksum"
},
"include_patterns": ["*.txt"],
"exclude_patterns": []
}
"manifests": {}
}
}
{
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
"integrity_profile": {
"type": "done_file",
"done_files_path": "/ETL/REMOTE-OUTBOX/DATA",
"include_patterns": ["*.md5"],
"exclude_patterns": []
},
"include_patterns": ["*.txt"],
"exclude_patterns": []
}
"manifests": {}
}
}
1.2.2 Manifests System
The Manfests System is a is a collection of properties that define where manifests for a given system are located as well as how to generate manifests. Below is an example of the Manifests System of a Remote Inbox ETL System Configuration (Data System ignored to simplify the schema)
{
"remote_outbox": {
"data": {}
"manifests": {
"system_id": "etl.userguide.systema.<user_id>",
"generation_policy": "auto_one_per_file",
"priority": "oldest",
"path": "/ETL/REMOTE-OUTBOX/MANIFESTS",
"include_patterns": [],
"exclude_patterns": []
}
}
}
system_id- The ID of Tapis System on which manifest files are stored or createdpath- The path to the directory on the Tapis System where the manifest files are stored or createdinclude_patterns- An array of glob patterns that are used to filter filenames. All files matching the glob patterns are considered by Tapis ETL to be manifest files.exclude_patterns- An array of glob patterns that are used to filter filenames. All files matching the glob patterns are considered by Tapis ETL to be non-manifest files.generation_policy- Indicates how manifests will be generated for data files on the Manifests System. Must be one of the following values:manual- A user must manually generate the manifests for the data files that they want their ETL Pipeline to processauto_one_per_file- Generates one manifest per data file found in the data directoryauto_one_for_all- Generates one manifests for all data files found in the data directory
priority- The order in which manifests should be processed. Must be one of the following valuesoldest- Tapis ETL will process the oldest manifest in the manifests pathnewest- Tapis ETL will process the newest manifest in the manifests pathany- Tapis ETL determine which manifests in the manifests path to process first
Note
- Section 1 Punch List
Created 1 Globus system with Tapis
Registered credentials with Tapis for the Globus system
Successully peformed a file listing with Tapis on the Globus system
Created 1 Linux system with Tapis
Registered credentials with Tapis for the Linux system
Successully peformed a file listing with Tapis on the Linux system
2. ETL Pipeline Creation
In this section we create our ETL Pipeline. Once it’s created, we will discuss each part of the ETL Pipeline schema in detail.
Note
This schema is built using data from resources that were created during the earlier sections of this User Guide.
2.1 Create the ETL Pipeline
Create an ETL Pipeline (createETLPipeline)
Save the following ETL pipeline definiton to a file named etl-pipeline.json in your current working directory.
{
"id": "etl-userguide-pipeline-<user_id>",
"before": null,
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"generation_policy": "auto_one_per_file",
"path": "/ETL/REMOTE-OUTBOX/MANIFESTS"
}
},
"local_inbox": {
"control": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/CONTROL"
},
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/MANIFESTS"
}
},
"jobs": [
{
"name": "sentiment-analysis",
"appId": "etl-sentiment-analysis-test",
"appVersion": "dev",
"nodeCount": 1,
"coresPerNode": 1,
"maxMinutes": 10,
"execSystemId": "test.etl.ls6.local.inbox",
"execSystemInputDir": "${JobWorkingDir}/jobs/${JobUUID}/input",
"archiveSystemId": "test.etl.ls6.local.inbox",
"archiveSystemDir": "ETL/LOCAL-OUTBOX/DATA",
"parameterSet": {
"schedulerOptions": [
{
"name": "allocation",
"arg": "-A TACC-ACI"
},
{
"name": "profile",
"arg": "--tapis-profile tacc-apptainer"
}
],
"containerArgs": [
{
"name": "input-mount",
"arg": "--bind $(pwd)/input:/src/input:ro,$(pwd)/output:/src/output:rw"
}
],
"archiveFilter": {
"includes": [],
"excludes": ["tapisjob.out"],
"includeLaunchFiles": false
}
}
}
],
"local_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/MANIFESTS"
}
},
"remote_inbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/REMOTE-INBOX/MANIFESTS"
}
},
"after": null
}
Then submit the definition.
with open('etl-pipeline.json', 'r') as file:
pipeline = json.load(file)
t.workflows.createETLPipeline(group_id=<group_id>, **pipeline)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/beta/groups/<group_id>/etl -d @etl-pipeline.json
Once created, you can now fetch and run the pipeline
t.workflows.getPipeline(group_id=<group_id>, pipeline_id=<pipeline_id>)
curl -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups/<group_id>/pipeline/<pipeline_id>
2.2 Remote Outbox
The Remote Outbox is the ETL System Configuration that tells Tapis ETL where data files to be processed are staged. Any data files placed on the Data System in the data directory (after applying the include and exclude pattern filters) are the files that will be processed during runs of an ETL Job.
How many get processed and in what order is determined by the manifests generated for those data files. Consider the schema below, specifically the Manifest Configuration.
{
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"generation_policy": "auto_one_per_file",
"path": "/ETL/REMOTE-OUTBOX/MANIFESTS"
}
}
This Manifest Configuration tells Tapis ETL that the user wants Tapis ETL to handle manifests generation.
According to the manifest generation policy of auto_one_per_file, Tapis ETL will generate one manifest
for each data file that is not currently being tracked in another manifest.
Warning
Using automatic manifest generation policies without specifying a data integrity profile can beak a pipeline.
The preferred manifest generation policy for the Remote Inbox is manual. Instructions for generating manifests
will come in the following sections.
For more info on other possible configurations, see the Manifests Configuration section
Tapis ETL will perform this operation for every untracked data file for every run of the pipeline. Whether this step
runs or not has no effect on the actual data processing phase of the pipeline run (the phase where the ETL Jobs are run).
If there are no data files to be tracked, Tapis ETL will simply move on to the next step; looking for an unprocessed manifest with a status of pending
and submitting it for processing.
2.3 Local Inbox
Tapis ETL will transfer all of the data files from the Remote Outbox to the data directory of the Local Inbox for processing.
Note
When configuring your Local Inbox, consider that your ETL Jobs should run on a system that has a shared file system with the Local Inbox. The data path in the Local Inboxes Data Configuration should be accessible to the first ETL Job.
Notice that this ETL System Configuration has an addition property, control. This is simply a place that
Tapis ETL will write accounting files to ensure the pipeline runs as expected. It is recommended that you use the same
system as in Local Inbox’s Manifest System, however any system to which Tapis ETL can write files to would work.
{
"control": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/CONTROL"
},
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/MANIFESTS"
}
}
2.4 ETL Jobs
ETL Jobs are an ordered list Tapis Job definitions that are dispatched and run serially during a pipeline’s transform phase. Tapis ETL dispatches these Tapis Jobs and uses the data files in a manifest as the inputs for the job. Once all of the ETL Jobs complete, the tranform phase ends.
[
{
"name": "sentiment-analysis",
"appId": "etl-sentiment-analysis-test",
"appVersion": "dev",
"nodeCount": 1,
"coresPerNode": 1,
"maxMinutes": 10,
"execSystemId": "test.etl.ls6.local.inbox",
"execSystemInputDir": "${JobWorkingDir}/jobs/${JobUUID}/input",
"archiveSystemId": "test.etl.ls6.local.inbox",
"archiveSystemDir": "ETL/LOCAL-OUTBOX/DATA",
"parameterSet": {
"schedulerOptions": [
{
"name": "allocation",
"arg": "-A TACC-ACI"
},
{
"name": "profile",
"arg": "--tapis-profile tacc-apptainer"
}
],
"containerArgs": [
{
"name": "input-mount",
"arg": "--bind $(pwd)/input:/src/input:ro,$(pwd)/output:/src/output:rw"
}
],
"archiveFilter": {
"includes": [],
"excludes": ["tapisjob.out"],
"includeLaunchFiles": false
}
}
}
]
- Every ETL Job is furnished with the following envrionment variables which can be accessed at runtime by your Tapis Job.
TAPIS_WORKFLOWS_TASK_ID- The ID of the Tapis Workflows task in the pipeline that is currently being executedTAPIS_WORKFLOWS_PIPELINE_ID- The ID of the Tapis Workflows Pipeline that is currently runningTAPIS_WORKFLOWS_PIPELINE_RUN_UUID- A UUID given to this specific run of the pipelineTAPIS_ETL_HOST_DATA_INPUT_DIR- The directory that contains the data files for inital ETL JobsTAPIS_ETL_HOST_DATA_OUTPUT_DIR- The directory to which output data files should be persistedTAPIS_ETL_MANIFEST_FILENAME- The name of the file that contains the manifestTAPIS_ETL_MANIFEST_PATH- The full path (including the filename) to the manifest fileTAPIS_ETL_MANIFEST_MIME_TYPE- The MIME type of the manifest file (alwaysapplication/json)
In addition to the envrionment variables, a fileInput for the manfiest file is added to the job definition to ensure that is available to the ETL Jobs runtime.
In your application code, you can use the envrionment variables above to locate the manifest file and inspect its contents.
This is useful if your application code does not know where to find its input data. The local_files array property of the manifest
contains the list of input data files. The files are represented as objects in the local_files array and take the following form.
{
"mimeType": null,
"type": "file",
"owner": "876245",
"group": "815499",
"nativePermissions": "rwxr-xr-x",
"url": "tapis://etl.userguide.systemb.<user_id>/ETL/LOCAL-INBOX",
"lastModified": "2024-02-26T22:51:31Z",
"name": "data1.txt",
"path": "ETL/LOCAL-INBOX/DATA/data1.txt",
"size": 66
}
2.5 Local Outbox
Once the Transform Phase ends, all of the output data files should be in the data directory of the Local Inbox. These files are then tracked in manifests to be transferred in the Egress Phase of the pipeline.
{
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/MANIFESTS"
}
}
2.6 Remote Inbox
During the Egress Phase, all of the output data produced by the ETL Jobs is transferred from the Local Outbox to the Remote Inbox. Once all of the data files from an Egress Manifest are successfully transferred over, Tapis ETL will then transfer that manifest to the manifests directory of the Remote Inbox system to indicate that files transfers are complete.
{
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/REMOTE-INBOX/MANIFESTS"
}
}
Note
- Section 2 Punch List
Created an ETL Pipeline
Can fetch the pipeline’s details from Tapis Workflows
3. Running an ETL Pipeline
In this section we will make our final preperations and perform our first pipeline run. This ETL Pipeline is configured to run HPC jobs that perform sentiment analysis on our data files. It is safe to trigger multiple pipeline runs with Tapis ETL. Tapis ETL has a system for locking down ETL resources (such as manifests) to prevent race conditions for data files. In other words, multiple pipelines can be running in parallel, all of which can be guaranteed to be processing entirely different data files.
3.1 Staging data files to the Remote Outbox
Before running an ETL Pipeline, you must first ensure that there are data files in the data directory of the Remote Outbox. Running a pipeline before there is any data staged to it would result in a “no-op” for each of the 3 phases of the ETL pipeline.
3.2 Manifests
Manifests
Manifests are JSON files that track one or more data files on a Data System as well as those data file’s progress through the various ETL Pipeline Phases. These manifest files contain a single manifest object that conforms to the schema below.
{
"status": "pending",
"phase": "ingress",
"local_files": [],
"transfers": [],
"remote_files": [
{
"mimeType": null,
"type": "file",
"owner": "876245",
"group": "815499",
"nativePermissions": "rwxr-xr-x",
"url": "tapis://etl.userguide.systemb.<user_id>/ETL/LOCAL-INBOX",
"lastModified": "2024-02-26T22:51:31Z",
"name": "data1.txt",
"path": "ETL/LOCAL-INBOX/DATA/data1.txt",
"size": 66
},
{
"mimeType": null,
"type": "dir",
"owner": "876245",
"group": "815499",
"nativePermissions": "rwxr-xr-x",
"url": "tapis://etl.userguide.systemb.<user_id>/ETL/LOCAL-INBOX/data2.txt",
"lastModified": "2024-02-26T22:51:38Z",
"name": "data2.txt",
"path": "ETL/LOCAL-INBOX/DATA/data2.txt",
"size": 47
}
],
"jobs": [],
"logs": [
"2024-04-01 19:16:49.378611 Created"
],
"created_at": 1711999009.378607,
"last_modified": 1711999009.378607,
"metadata": {}
}
3.3 Generating Manifests
For each data file or set of data files in the Remote Outbox that you want to run an ETL Job against, you will need to generate a manifest for them. Each manifest in the Remote Inbox corresponds with a single Transform, or ETL Job. Each data file in a single manifest will be used as input files for a single ETL Job.
There are two ways to generate manifest files. Manually and automatically. Automatic manifest generation is the simplest
manifest generation policy to use but the least flexible. With automatic manifest generation, you can use the auto_one_for_all policy and generate a manifest
for all untracked files in the data directory, or the auto_one_per_file and generate one manifest per file in the data directory.
For all situations in which you need to generate manifests for arbitrary files in the Remote Inbox, you must use the manual manifest generation policy
Note
Coming Soon - Manual manifest generation
If you are following the tutorial in the user guide, we previously configured our Remote Inbox to have a manifest generation policy of
auto_one_per_file so Tapis ETL will generate the manifest for our data1.txt data file that we created in the previous step.
3.4 Run the Pipeline
Now that we have a data file (data1.txt) and a manifest tracking that data file, we can trigger the first run of our ETL Pipeline.
Run an ETL Pipeline (runPipeline)
- To run a pipeline, you must:
Provide the
idof the group that owns the pipelineProvide the
idof the pipelineBelong to the group that owns the pipeline
Pipeline Arguments
- When running an ETL Pipeline with Tapis ETL, you must provide the following arguments:
TAPIS_USERNAME- Username of the Tapis user running the pipelineTAPIS_PASSWORD- Password of the userTAPIS_BASEURL- The URL of the Tapis Tenant in which your pipeline should run (should be the same as the base URL you used to create your pipeline)
Save the following Pipeline Args definiton to a file named etl-pipeline-args.json in your current working directory.
{
"args": {
"TAPIS_USERNAME": {
"type": "string",
"value": "<tapis_username>"
},
"TAPIS_PASSWORD": {
"type": "string",
"value": "<tapis_password>"
},
"TAPIS_BASE_URL": {
"type": "string",
"value": "https://tacc.tapis.io"
}
}
}
Then submit the definition.
with open('pipeline-args.json', 'r') as file:
args = json.load(file)
t.workflows.runPipeline(group_id=<group_id>, pipeline_id=<pipeline_id>, args=args)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/beta/groups/<group_id>/etl -d @etl-pipeline.json
3.5 Check the status of the Pipeline Run
Fetch Pipeline Run Details (getPipelineRun)
Fetch the details of a single pipeline run. You will need the following data.
* group_id - id of the group that owns the pipeline
* pipeline_id - id of the pipeline
* pipeline_run_uuid - UUID of the pipeline run
t.workflows.getPipelineRun(group_id=<group_id>, pipeline_id=<pipeline_id>)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups/<group_id>/pipeline/<pipeline_id>/runs/<pipeline_run_uuid>
3.6 Pipeline Run Complete
Once the pipeline has gone through the 3 phases, the ETL Pipeline will enter a terminal state of either completed or failed.
- Here are the most common reasons why an ETL Pipeline may fail.
Ingress transfer failed (Remote Outbox to Local Inbox)
Egress transfer failed (Local Outbox to Remote Inbox)
Malformed manifest - This is a critical and unrecoverable error
One of the batch compute jobs (ETL Jobs) exited with a non-zero exit code
4. Resubmitting a Pipeline Run
Coming Soon
Quick Start
- In this section we will be constructing an ETL pipeline that:
Detects the presence of data files and manifests on some remote system
Transfers those manifests and data files to a local system
Performs sentiment analysis on the text content of the data files and generates a result file for each analysis
Transfers the results files to a remote system for archiving
In this step, we will create the following prerequisite Tapis resources:
One group (Workflows API) - A collection of Tapis users that collectively own workflow resources
Two (or more) systems (Systems API) - Tapis Systems for the Data and Manifests Configuration for the ETL Systems of your pipeline. We will create 1 Globus-type system for data transfers and storage, and 1 Linux-type system that we will use for manifests and compute.
Creating a Group (createGroup)
Create a file in your current working directory called group.json with the following json schema:
{
"id": "<group_id>",
"users": [
{
"username":"<user_id>",
"is_admin": false
}
]
}
Note
You do not need to add your own Tapis id to the users list. The owner of the Group is added by default.
Replace <group_id> with your desired group id and <user_id> in the user objects with the ids of any other Tapis users that you want to have access to your workflows resources.
Warning
Users with is_admin flag set to true can perform every action on all Workflow resources in a Group except for
deleting the Group itself (only the Group owner has those permissions)
Submit the definition.
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups -d @group.json
import json
from tapipy.tapis import Tapis
t = Tapis(base_url='https://tacc.tapis.io', username='<userid>', password='************')
t.get_tokens()
with open('group.json', 'r') as file:
group = json.load(file)
t.workflows.createGroup(**group)
Creating a Globus System for an ETL Pipeline
Create a file named onsite-globus-system.json in your current working directory that contains the json schema below.
{
"id": "etl.userguide.systema.<user_id>",
"description": "Tapis ETL Globus System on LS6 for data transfer and storage",
"canExec": false,
"systemType": "GLOBUS",
"host": "24bc4499-6a3a-47a4-b6fd-a642532fd949",
"defaultAuthnMethod": "TOKEN",
"rootDir": "HOST_EVAL($SCRATCH)"
}
import json
from tapipy.tapis import Tapis
t = Tapis(base_url='https://tacc.tapis.io', username='<userid>', password='************')
t.tokens.get_tokens()
with open('onsite-globus-system.json', 'r') as file:
system = json.load(file)
t.systems.createSystem(**system)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/systems -d @onsite-globus-system.json
Register Globus Credentials for the System
Once you have successfully created the system, you must then register credentials for the system in order for Tapis to access it on your behalf. Follow the instructions found in the Registering Globus Credentials for a System section.
Once you have successfully registered credentials for the system, you should be able to list files on the system.
Creating a Linux System for an ETL Pipeline
Create a file named onsite-linux-system.json in your current working directory that contains the json schema below.
{
"id": "etl.userguide.systemb.<user_id>",
"description": "Tapis ETL Linux System on LS6 for manifests and compute",
"systemType": "LINUX",
"host": "ls6.tacc.utexas.edu",
"defaultAuthnMethod": "PKI_KEYS",
"rootDir": "HOST_EVAL($SCRATCH)",
"canExec": true,
"canRunBatch": true,
"jobRuntimes": [
{
"runtimeType": "SINGULARITY",
"version": null
}
],
"batchLogicalQueues": [
{
"name": "ls6-normal",
"hpcQueueName": "normal",
"maxJobs": 1,
"maxJobsPerUser": 1,
"minNodeCount": 1,
"maxNodeCount": 2,
"minCoresPerNode": 1,
"maxCoresPerNode": 2,
"minMemoryMB": 0,
"maxMemoryMB": 4096,
"minMinutes": 10,
"maxMinutes": 100
},
{
"name": "ls6-development",
"hpcQueueName": "development",
"maxJobs": 1,
"maxJobsPerUser": 1,
"minNodeCount": 1,
"maxNodeCount": 2,
"minCoresPerNode": 1,
"maxCoresPerNode": 2,
"minMemoryMB": 0,
"maxMemoryMB": 4096,
"minMinutes": 10,
"maxMinutes": 100
}
],
"batchDefaultLogicalQueue": "ls6-development",
"batchScheduler": "SLURM",
"batchSchedulerProfile": "tacc-apptainer"
}
Use one of the following methods to submit a request to the Systems API to create the Tapis System.
with open('onsite-linux-system.json', 'r') as file:
system = json.load(file)
t.systems.createSystem(**system)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/systems -d @onsite-linux-system.json
Register Credentials for the System
Once you have successfully created the system, you must then register credentials for the system in order for Tapis to access it on your behalf. Follow the instructions found in the Registering Credentials for a System section.
Once you have successfully registered credentials for the system, you should be able to list files on the system.
Create an ETL Pipeline (createETLPipeline)
Save the following ETL pipeline definiton to a file named etl-pipeline.json in your current working directory.
{
"id": "etl-userguide-pipeline-<user_id>",
"before": null,
"remote_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-OUTBOX/DATA",
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"generation_policy": "auto_one_per_file",
"path": "/ETL/REMOTE-OUTBOX/MANIFESTS"
}
},
"local_inbox": {
"control": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/CONTROL"
},
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-INBOX/MANIFESTS"
}
},
"jobs": [
{
"name": "sentiment-analysis",
"appId": "etl-sentiment-analysis-test",
"appVersion": "dev",
"nodeCount": 1,
"coresPerNode": 1,
"maxMinutes": 10,
"execSystemId": "test.etl.ls6.local.inbox",
"execSystemInputDir": "${JobWorkingDir}/jobs/${JobUUID}/input",
"archiveSystemId": "test.etl.ls6.local.inbox",
"archiveSystemDir": "ETL/LOCAL-OUTBOX/DATA",
"parameterSet": {
"schedulerOptions": [
{
"name": "allocation",
"arg": "-A TACC-ACI"
},
{
"name": "profile",
"arg": "--tapis-profile tacc-apptainer"
}
],
"containerArgs": [
{
"name": "input-mount",
"arg": "--bind $(pwd)/input:/src/input:ro,$(pwd)/output:/src/output:rw"
}
],
"archiveFilter": {
"includes": [],
"excludes": ["tapisjob.out"],
"includeLaunchFiles": false
}
}
}
],
"local_outbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/LOCAL-OUTBOX/MANIFESTS"
}
},
"remote_inbox": {
"data": {
"system_id": "etl.userguide.systema.<user_id>",
"path": "/ETL/REMOTE-INBOX/DATA"
},
"manifests": {
"system_id": "etl.userguide.systemb.<user_id>",
"path": "/ETL/REMOTE-INBOX/MANIFESTS"
}
},
"after": null
}
Then submit the definition.
with open('etl-pipeline.json', 'r') as file:
pipeline = json.load(file)
t.workflows.createETLPipeline(group_id=<group_id>, **pipeline)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/beta/groups/<group_id>/etl -d @etl-pipeline.json
Once created, you can now fetch and run the pipeline
t.workflows.getPipeline(group_id=<group_id>, pipeline_id=<pipeline_id>)
curl -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups/<group_id>/pipeline/<pipeline_id>
Run an ETL Pipeline (runPipeline)
- To run a pipeline, you must:
Provide the
idof the group that owns the pipelineProvide the
idof the pipelineBelong to the group that owns the pipeline
Pipeline Arguments
- When running an ETL Pipeline with Tapis ETL, you must provide the following arguments:
TAPIS_USERNAME- Username of the Tapis user running the pipelineTAPIS_PASSWORD- Password of the userTAPIS_BASEURL- The URL of the Tapis Tenant in which your pipeline should run (should be the same as the base URL you used to create your pipeline)
Save the following Pipeline Args definiton to a file named etl-pipeline-args.json in your current working directory.
{
"args": {
"TAPIS_USERNAME": {
"type": "string",
"value": "<tapis_username>"
},
"TAPIS_PASSWORD": {
"type": "string",
"value": "<tapis_password>"
},
"TAPIS_BASE_URL": {
"type": "string",
"value": "https://tacc.tapis.io"
}
}
}
Then submit the definition.
with open('pipeline-args.json', 'r') as file:
args = json.load(file)
t.workflows.runPipeline(group_id=<group_id>, pipeline_id=<pipeline_id>, args=args)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/beta/groups/<group_id>/etl -d @etl-pipeline.json
Fetch Pipeline Run Details (getPipelineRun)
Fetch the details of a single pipeline run. You will need the following data.
* group_id - id of the group that owns the pipeline
* pipeline_id - id of the pipeline
* pipeline_run_uuid - UUID of the pipeline run
t.workflows.getPipelineRun(group_id=<group_id>, pipeline_id=<pipeline_id>)
curl -X POST -H "content-type: application/json" -H "X-Tapis-Token: $JWT" https://tacc.tapis.io/v3/workflows/groups/<group_id>/pipeline/<pipeline_id>/runs/<pipeline_run_uuid>
Tapis V3 CLI is required for this interactive tutorial. Instructions for installing Tapis V3 CLI can be found in the README.md of the project Github (Does not require root privileges)
Warning
This tutorial drastically simplifies the ETL pipeline setup and creation process. We will be assuming that you have all of the requisite storage and compute allocations as well as access to all the HPC systems at your chosen data center. If you want a more in-depth tutorial that explains important Tapis ETL concepts along the way, follow the User Guide
Coming Soon